Hello.
My question is this:
Is there any block in OB2 to convert the value & to unicode code whose result would be \u0026?
Hello, I think you can use the translate block. Otherwise do it in C# directly.
Thanks Ruri for your advice but if I wanted to do it in C# it would be interesting, how would it have to be done?
BLOCK:Unescape
input = @
=> VAR @unescapeOutput
ENDBLOCK
I don’t understand the unescape block in this thread but I’ve already solved it as Ruri told me. Anyway I would like to do it in C#, clarifying that several characters similar to & can appear in the PASS variable as I show below.
BLOCK:Translate
LABEL:PASS
input = @input.PASS
translations = {(“&”, “\u0026”), (“\”, “\\”), (“"”, “\"”), (“=”, “\u003d”), (“'”, “\u0027”), (“<”, “\u003c”), (“>”, “\u003e”)}
=> VAR @PASS
ENDBLOCK
Alright so this shit is super fucking overkill, And would probably be better as just a plugin block, but here
public class UnicodeConverter
{
public string Input { get; set; }
public List<string> UnicodeValues { get; private set; }
public UnicodeConverter(string input)
{
Input = input;
UnicodeValues = ConvertToUnicodeValues(Input);
}
private List<string> ConvertToUnicodeValues(string input)
{
List<string> unicodeList = new List<string>();
foreach (char c in input)
{
string unicodeValue = GetUnicodeValue(c);
unicodeList.Add(unicodeValue);
}
return unicodeList;
}
private string GetUnicodeValue(char c)
{
return "\\u" + ((int)c).ToString("X4");
}
public string GetSymbolUnicodeString()
{
StringBuilder result = new StringBuilder();
foreach (char c in Input)
{
if (char.IsSymbol(c) || char.IsPunctuation(c))
{
result.Append(GetUnicodeValue(c));
}
else
{
result.Append(c);
}
}
return result.ToString();
}
}
BLOCK:ConstantString
value = "ThisIsAStringWithUnicodeSymbolsInIt$^%#!%^&(^$$%#^&"
=> VAR @constantStringOutput
ENDBLOCK
// Create converter
var converter = new UnicodeConverter(constantStringOutput);
// Gets output from converter
string output = converter.GetSymbolUnicodeString();
LOG output
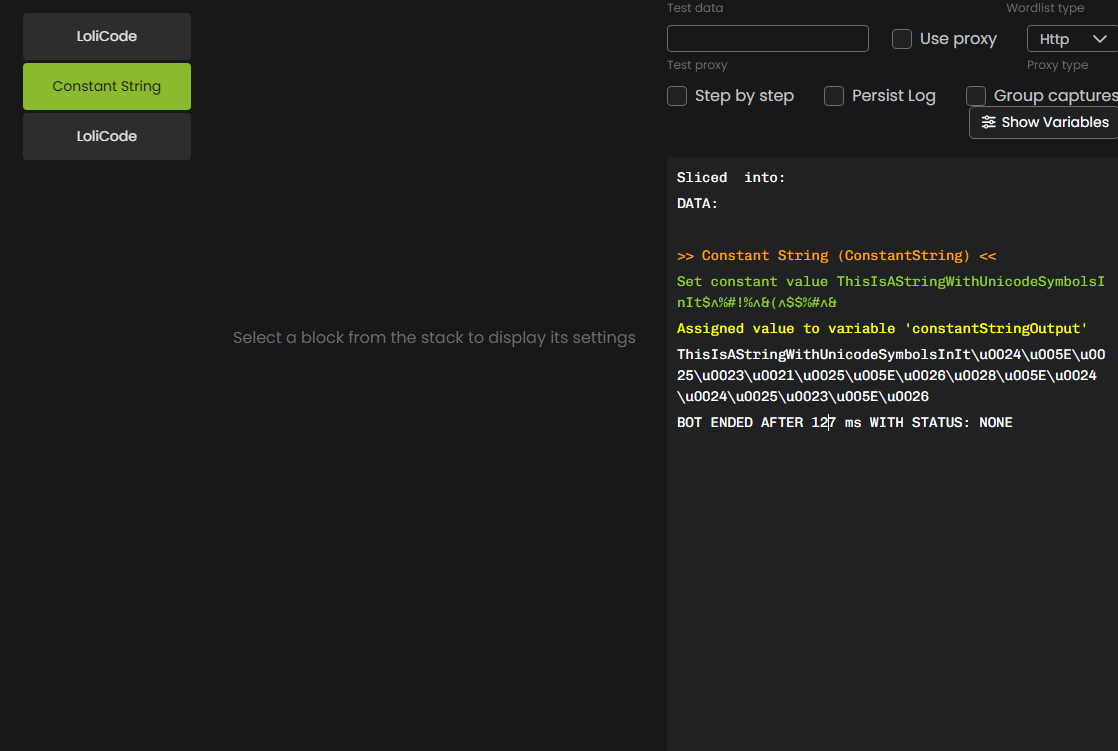
This lolicode will take a string and convert any symbols in the string to unicode values, then rebuild the string.
example:
Input: ThisIsAStringWithUnicodeSymbolsInIt$^%#!%^&(^$$%#^&
Output:ThisIsAStringWithUnicodeSymbolsInIt\u0024\u005E\u0025\u0023\u0021\u0025\u005E\u0026\u0028\u005E\u0024\u0024\u0025\u0023\u005E\u0026
you can replace the ConstantString block with input.PASS to pass in the password
Keep in mind you will need to add System.Text in the usings tab.
Edit: I stopped programming about 2 years ago to pursue art instead so this code is probably disgusting, but it works.
1 Like
I think programming is less boring than art, but everyone has their own preferences. As for the issue, it works correctly, but the characters \ and " are not encoded in unicode, but the output format is an escape string. Should the code be modified? How would I make it work correctly?
public class UnicodeConverter
{
public string Input { get; set; }
public List<string> UnicodeValues { get; private set; }
public UnicodeConverter(string input)
{
Input = input;
UnicodeValues = ConvertToUnicodeValues(Input);
}
private List<string> ConvertToUnicodeValues(string input)
{
List<string> unicodeList = new List<string>();
foreach (char c in input)
{
// Exclude double quotes and backslashes from conversion
if (c != '"' && c != '\\')
{
string unicodeValue = GetUnicodeValue(c);
unicodeList.Add(unicodeValue);
}
else
{
unicodeList.Add(c.ToString()); // Add the character as is
}
}
return unicodeList;
}
private string GetUnicodeValue(char c)
{
return "\\u" + ((int)c).ToString("X4");
}
public string GetSymbolUnicodeString()
{
StringBuilder result = new StringBuilder();
foreach (char c in Input)
{
// Exclude double quotes and backslashes from conversion
if ((char.IsSymbol(c) || char.IsPunctuation(c)) && c != '"' && c != '\\')
{
result.Append(GetUnicodeValue(c));
}
else
{
result.Append(c);
}
}
return result.ToString();
}
}
// Create converter
var converter = new UnicodeConverter(@input.PASS);
// Gets output from converter
string output = converter.GetSymbolUnicodeString();
LOG output
This updated code should stop " and \ from being converted.
1 Like
Thank you very much for sharing your knowledge.