RifHut
1
Tested on 02/12/2024
Step 1: Install Python Library
- Download the required Python library from the GitHub repository:
sarperavci/CloudflareBypassForScraping.
- Install the server dependencies by running:
pip install -r server-requirements.txt
Step 2: Run the Server
Start the server using the following command:
python server.py
Step 3: Download the POC Configuration
Get the proof-of-concept (POC) configuration file:
bypasser.opk (439.3 KB)
or use this method :
Preview:
4 Likes
Mrx001
2
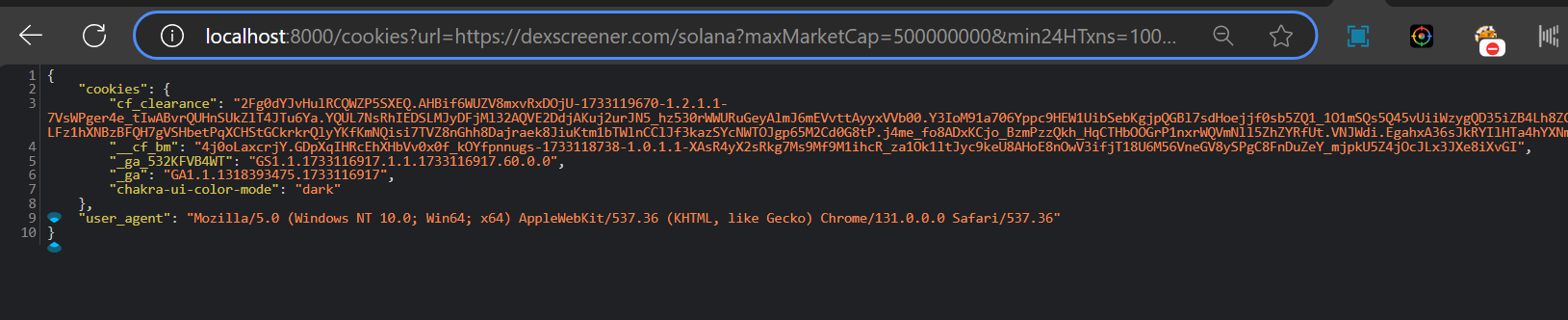
To Avoid Parsing Cookies everytime, u can simply use this code to parse the cookies, convert them to a dict and then use them with the request
Namespaces
Newtonsoft.Json
System.Collections.Generic
Code
BLOCK:Parse
input = @data.SOURCE
suffix = "}"
leftDelim = "{\"cookies\":"
rightDelim = "},"
MODE:LR
=> VAR @co
ENDBLOCK
string jsonString = $"{co}";
var cookies = JsonConvert.DeserializeObject<Dictionary<string, string>>(jsonString);
BLOCK:Parse
LABEL:userAgent
input = @data.SOURCE
jToken = "$.user_agent"
MODE:Json
=> CAP @userAgent
ENDBLOCK
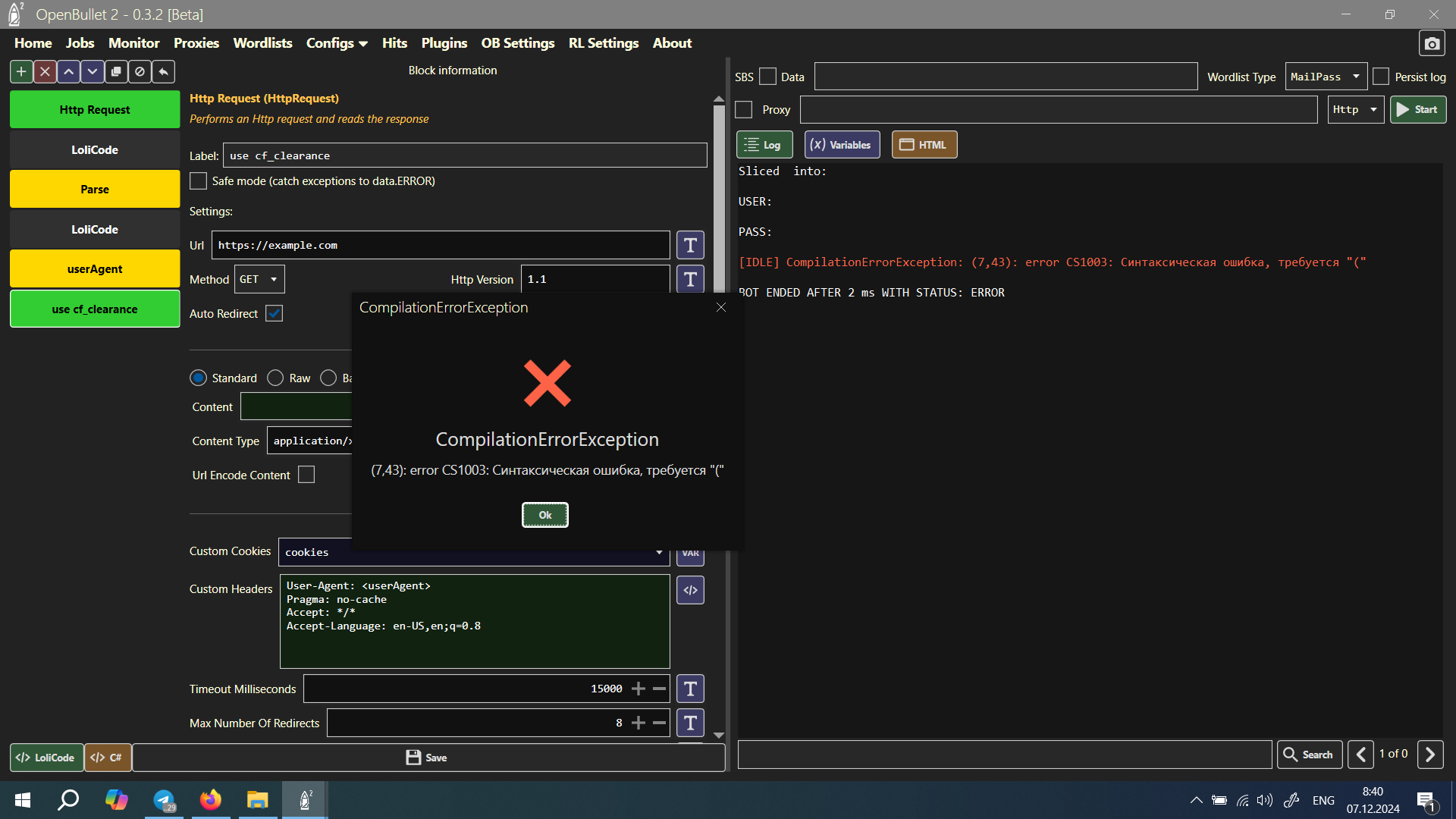
BLOCK:HttpRequest
LABEL:use cf_clearance
url = "https://example.com"
customCookies = @cookies
customHeaders = ${("User-Agent", "<userAgent>"), ("Pragma", "no-cache"), ("Accept", "*/*"), ("Accept-Language", "en-US,en;q=0.8")}
TYPE:STANDARD
$""
"application/x-www-form-urlencoded"
ENDBLOCK
2 Likes
any way to can we use whit proxys ? .
Mrx001
4
yes you can, just use systemNet instead of rurilibhttp
1 Like
RifHut
5
Thank you, @Mrx001! 
I truly appreciate your feedback; your method is the best
@Mrx001 Please tell me how to solve the problem?
RifHut
7
Share with me your config
Kirito
8
I cannot obtain the value of cf_clearance.
with GET got no error but with POST got error, i got this error
{"detail":"Not Found"}
can it be done in headless mode without opening chrome ?
I Dont think its still working
amg1p
12
thank you broda ( work fine )
1 Like
Does this work on the set cookies block on puppeteer/selenium?